今回の記事の重要ポイント(三点)
・OpenAIはImages 2.0で、文字表現、構図、一貫性など、これまで弱点とされやすかった画像の実用領域を強化した。
・今回の更新で焦点になっているのは画質競争ではなく、調査、構成、画像化までを一つの流れで支える統合環境の競争だ。
・先に変わるのは完成作品より中間制作物の制作工程であり、その一方で偽資料や偽図解のような「整った誤情報」の負担も重くなる。
ニュース
OpenAIは4月21日、ChatGPT向けの新しい画像生成モデル「ChatGPT Images 2.0」を発表した。画像内テキストの精度向上や高度な視覚推論が主な強化点とされ、有料プランでは生成前に構成を考える「images with thinking」も導入された。
続いて4月23日には最新モデル「GPT-5.5」も発表された。GPT-5.5は、コーディング、調査、情報分析、文書作成などに強いモデルと位置づけられており、今回の一連の発表でChatGPTは文章生成だけでなく、画像制作や実務支援まで含む統合型AIツールとしての性格をさらに強めた。
関連記事
補足説明
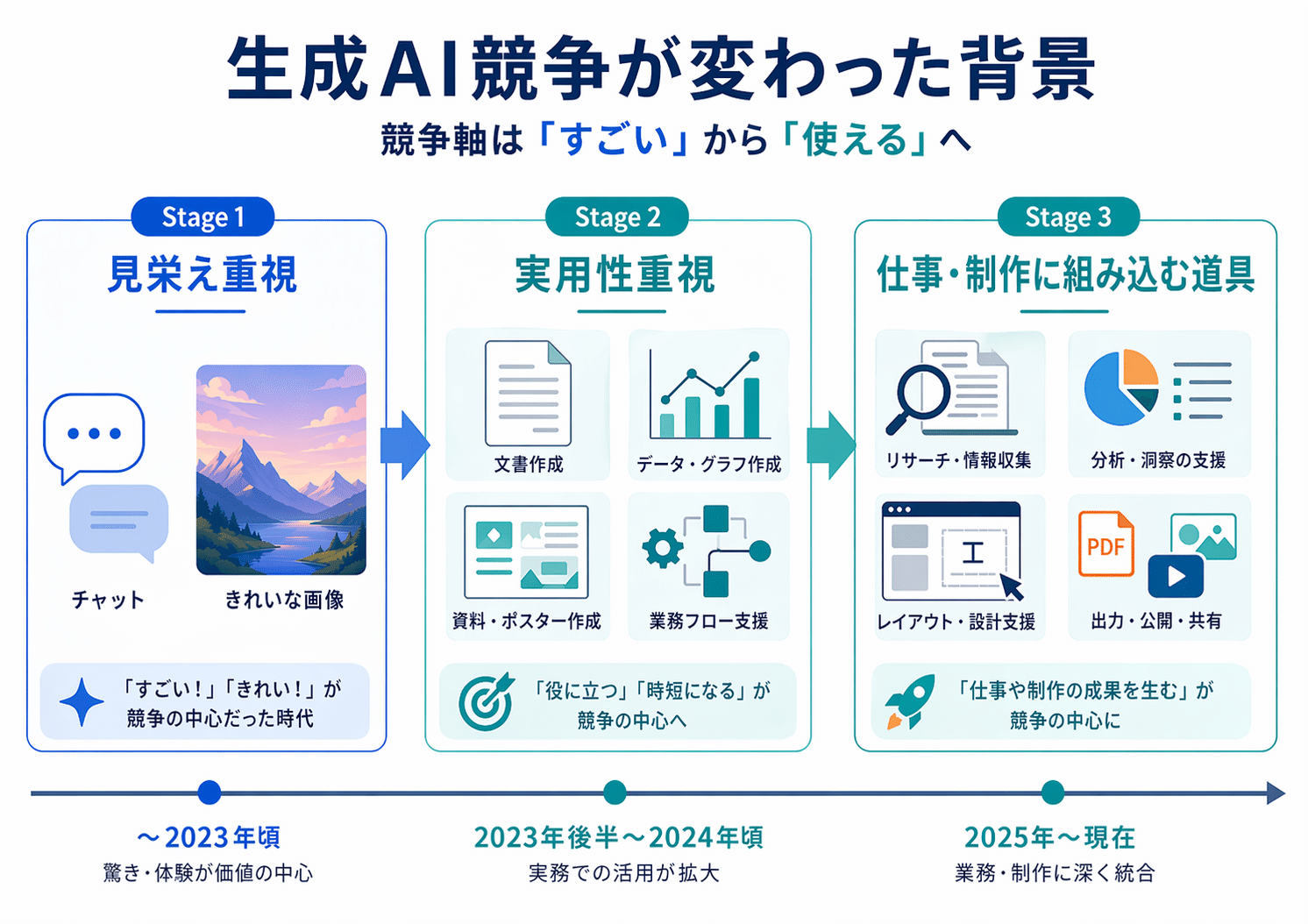
生成AI競争が変わった背景
この1年で、生成AIの競争軸はかなり変わりました。
以前は、文章がどれだけ自然に書けるか、画像がどれだけきれいに出せるかが注目されていましたが、最近はそこから一歩進み、実際の制作や業務でどこまで使えるかが重視されるようになっています。
画像でいえば、雰囲気のある1枚を出せるだけでは足りません。文字を崩さず入れられるか、複数の要素を整理して並べられるか、同じ人物やキャラクターを別カットでも保てるかが問われるようになっていました。
生成AIは「すごい技術」から「使えないと困る道具」へ近づいていたわけです。
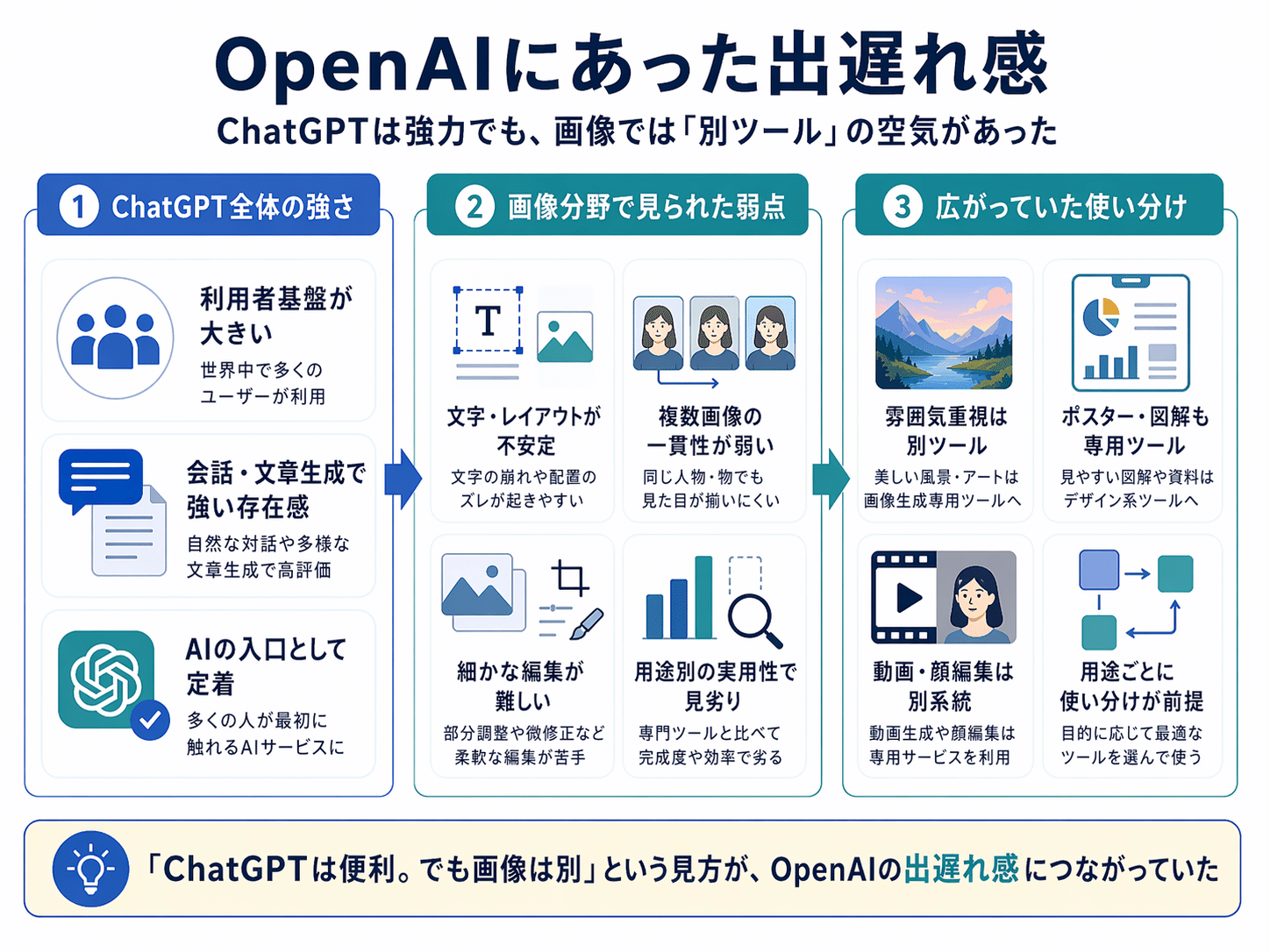
OpenAIにあった出遅れ感
その中で、OpenAIはすべての領域で常に先頭を走っているようには見られていませんでした。ChatGPTそのものの存在感は大きくても、画像生成では、きれいな画像は出せても文字やレイアウトはまだ弱い、実用面では専用ツールに一歩譲る、という印象が残っていたためです。
特に、ポスターや図解のように構成力が問われる画像では、雰囲気の良さだけでは評価されにくくなっていました。
動画や高度な編集も含めると、用途ごとに別の特化ツールを使い分けるのが当たり前という空気も強く、ChatGPTは便利でも画像は別、という見方が広がっていたのも事実です。
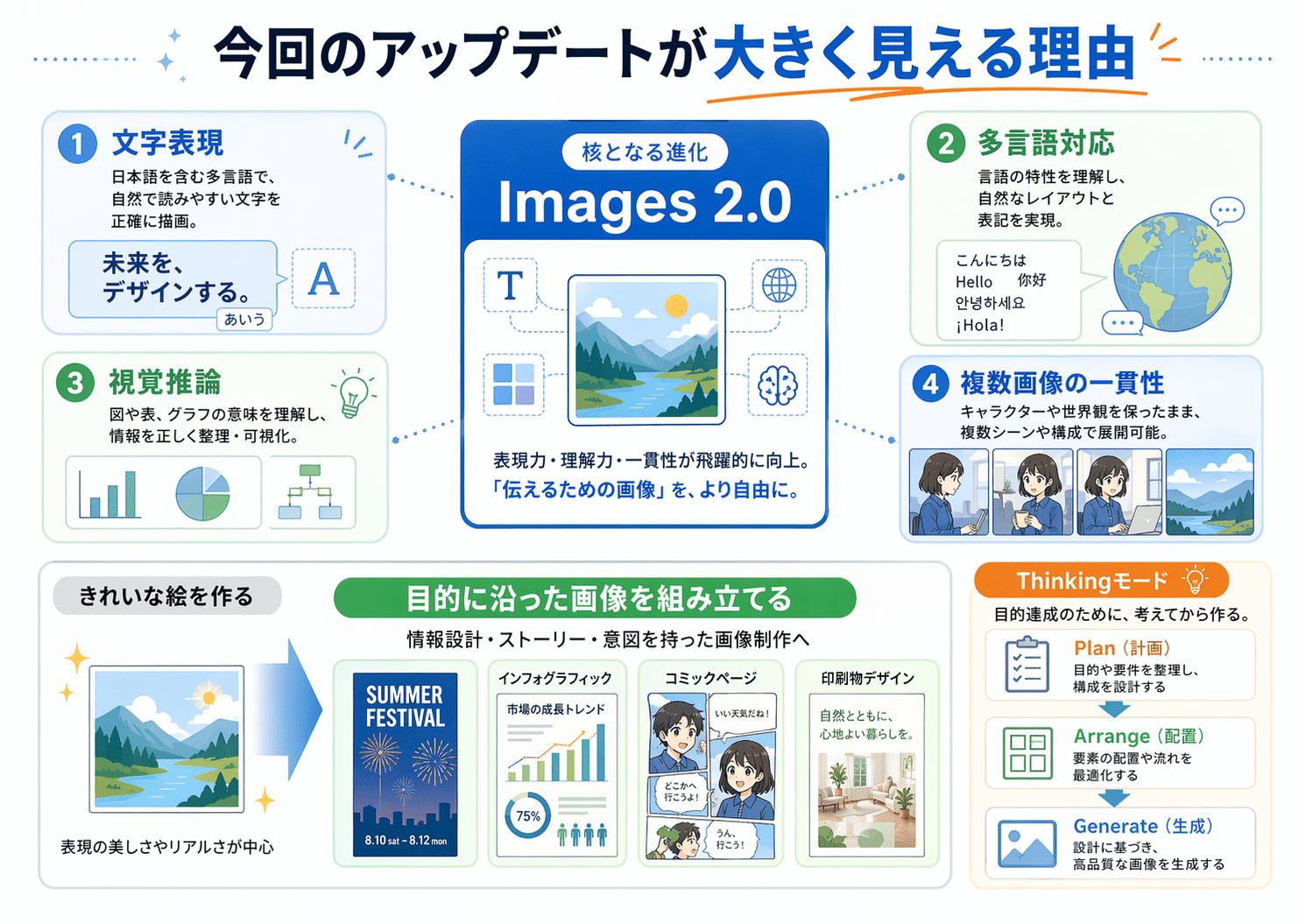
今回のアップデートが大きく見える理由
だからこそ、今回のImages 2.0は単なる画質向上では終わりません。注目されたのは、テキスト描画、多言語対応、高度な視覚推論、複数画像の一貫性といった、これまで弱点になりやすかった部分です。
画像生成AIは長く、雰囲気のいい1枚を出すところまでは強くても、文字が崩れる、構図が破綻する、連続した画像で人物が別物になるといった問題を抱えていました。今回の更新は、その壁を一気に越えたとまでは言えなくても、少なくとも明確に削りにきた内容になっています。
誌面風レイアウト、漫画ページ、図解、印刷用デザインのように、見せ方そのものを含んだ画像が前面に出てきたことで、生成AIは「きれいな絵を作る道具」から「目的に沿った画像を組み立てる道具」へ一歩進みました。
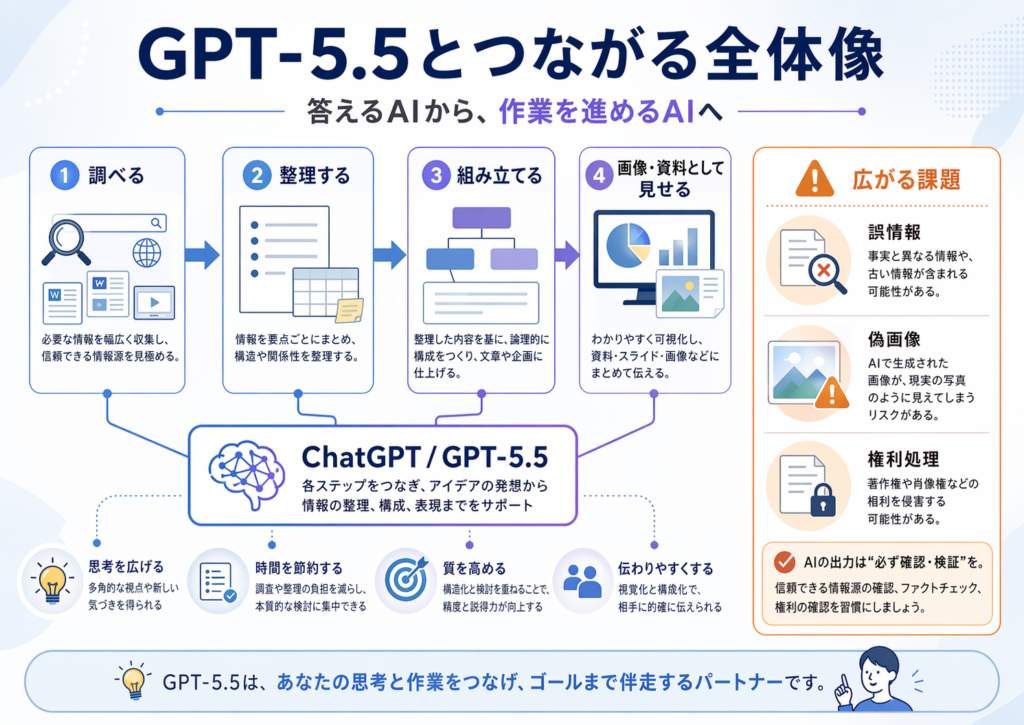
GPT-5.5とつながる全体像
今回の画像生成強化がより大きく見えるのは、同じ時期にGPT-5.5も打ち出されたからです。新モデルは、コーディング、調査、情報分析、文書作成、データ分析のような複雑な仕事に向く方向が強調されており、ChatGPT全体が「答えるAI」から「作業を進めるAI」へ移っている流れがはっきりしてきました。
画像生成の進化も、その一部として見る方が自然です。調べる、整理する、組み立てる、そして画像や資料として見せるところまで、一つの環境でつなごうとしているからです。
その一方で、進化が大きいほど課題も重くなります。文字が読める画像やもっともらしい図解が作りやすくなるほど、誤情報や偽画像のリスクも高まります。今回のアップデートは大きな前進ですが、便利になっただけでなく、生成AIがより重い責任を伴う段階に入ったことも示しています。
海外の反応
以下はスレッド内のユーザーコメントの抜粋・翻訳です。
いちばん驚いたのは、前より10倍くらい複雑なことをやれてるのに、1枚ごとの待ち時間はそこまで伸びてない。もっと重くなると思ってた。
自分もかなり驚いた。めちゃくちゃ単純なプロンプトでも、普通にいい結果が出る。
「マインクラフトの中にラスベガス・スフィアのスクリーンショットを作って」って頼んだら、他のモデルみたいに適当にそれっぽく済ませず、ちゃんと周囲のラスベガスの街並みまで出してきた。
ちょっと触っただけでも、もう他のモデルを使いたくなくなる感じはある。
グリッドとかレイアウトの精度の上がり方はかなり大きいと思う。
前に失敗した3×3とか5×5のプロンプトで試すと、どこまで安定したかすぐ分かる。そういう古い失敗プロンプトって、世代差を見るのに一番いいんだよな。
そう。移行する価値があるアップグレードかどうか見るなら、そういうので試すのが一番分かりやすい。
Geminiと横に並べて試してるけど、空間認識、被写界深度、ショット間の一貫性はGPTの方がかなり強い。
別々のキャラを作ってから1枚にまとめても、足の動きも立ち位置も背景までかなり自然につないでくる。まだ入口なんだろうけど、それでも結構すごい。
これ、複雑な図表っぽいものまで行けるってことだよな。地図みたいなのをどこまでやれるのか気になる。
これはいつもの「ちょっと良くなりました」じゃない。かなり別物に近いと思う。
本当にそう。単なる改良というより、一段階上に行った感じがある。
文字表現が一段変わったのは本当だと思う。
レストランのメニューとかSNS用グラフィックとか、インフォグラフィックのレイアウトとか、半年前なら使い物にならなかった。
たぶん肝はThinkingモードだな。前みたいに適当にピクセル並べて、たまたま文字が乗るのを祈る感じじゃなくなってる。
ChatGPTは、文字とレイアウトが必要な静止画ではかなり強いと思う。そこはもう明確に使い道がある。
逆に、雰囲気重視のアートっぽい絵はまだ他のツールの方が好みって人も多そう。
動画生成はやめたのに画像生成は続けるんだな。そこはちょっと意外だった。
OpenAI、「Sora」終了へ – ITmedia NEWS
まあ動画は高コストだったんだろうな。みんな数本ミーム動画を作って終わりだったし、完璧なものを安定して出せなかった。画像の方が安いし、安定してるし、ちゃんと使い道があるから金を払う人も多い。
数時間使ってみて思ったけど、できることとできないことの線引きはかなりはっきりしてる。
静止画はかなり良くなった。でも画像を短い動画にするとか、顔を差し替えるとか、リップシンクとか、そういうのはまだ別ツールが必要。
AIヘッドショットも、ちゃんと「その人の顔」になるところまではまだ行ってない感じがする。
結局、複数のツールを組み合わせる必要はまだあるってことだな。
それでも、静止画だけで見ればかなり実用的なレベルに近づいてると思う。
OpenAIはかなり先頭を走ってると思う。でも埋めないといけない穴がまだ結構あるのも確かだな。
考察・分析
OpenAIが取りにいくのは画質の王座ではない
今回の更新では、画像生成の性能向上そのものより、OpenAIがどこを取りにいこうとしているかが見えやすくなりました。焦点になっているのは、最も美しい一枚を出すことより、制作や業務の流れの中で使いやすい環境を押さえることです。
画像生成市場では長く、どのモデルがいちばん印象的な絵を出せるかが注目されてきました。ところが利用が広がるにつれて、実際に価値を持ち始めたのは、検索、要約、構成、画像化、資料化までを一つの流れで回せることでした。見栄えの良い画像を一枚作れることより、仕事の途中で何度も必要になる素材を安定して出せることの方が、現場では重くなっています。
Images 2.0も、その流れの中で位置づけると分かりやすいです。OpenAIは画質だけで競うのではなく、ChatGPTの中で文章、調査、構成、画像までつなげる方向を強めています。今回の更新は、その輪郭をかなりはっきり見せた発表でした。
先に揺れるのは完成作品より中間制作物
影響が先に出やすいのは、完成されたアート作品の世界よりも、その手前にある大量の中間制作物です。ポスターのたたき台、広告のラフ、説明図、販促素材、資料用ビジュアル、漫画やストーリーボードの試作のように、速さと構成力が求められる領域ほど変化を受けやすくなります。
この種の制作物では、最高レベルの芸術性より、短時間で複数案を出せること、文字や構図が大きく崩れないこと、用途に合わせて整えられることが重視されます。今回の更新が強く刺さるのは、その条件にかなり近づいたからです。
ここで変わるのは作品の価値そのものというより、作り方です。案を出す、並べる、比較する、修正する、見せ方を整える。その前半工程が軽くなるほど、AIは創作の周辺ではなく制作工程の中心に近づいていきます。
Claude Codeが先に作った「工程を担うAI」の空気
この流れは画像分野だけで起きているものではありません。開発の領域では、Claude Codeがすでに「質問に答えるAI」ではなく、「継続して作業を進めるAI」の空気を先に作っていました。コードを提案するだけでなく、ファイルを読み、修正し、複数の工程をまたぎながら仕事を進める使われ方が広がったことで、AIへの期待そのものが変わってきたからです。
その意味で、今回のOpenAIの動きはかなり分かりやすいです。開発ではCodex、文章や調査ではGPT-5.5、画像や図解ではImages 2.0という形で、製品ごとに役割は違っていても、向いている方向は共通しています。単発で出力することより、工程を引き受けることに重心が移っています。
今回の動きは、ChatGPTの画像機能の強化として見るだけでは収まりません。OpenAI全体の並びで見ると、工程を担うAIの競争に、画像や資料制作の側から本格的に踏み込んできた流れとして見えてきます。
SaaSの黙示録「SaaSpocalypse」 とマイクロソフト株急落、AIエージェントが揺らす人数課金モデル – せかはん(世界の反応)
強くなるのは偽写真より「整った誤情報」
性能向上の裏で、もう一つ重くなるのが情報空間の負担です。問題になりやすいのは偽写真ですが、今回より厄介なのは、文字が読める画像、もっともらしい図解、実在の資料や告知画面に見える画像が増えることです。
人は、見た目が整っているものを、内容まで正しいと受け取りやすい傾向があります。図解になっている、資料の形をしている、きれいに整理されている。それだけで信頼してしまうことは珍しくありません。今後増えるリスクは、衝撃的な偽写真より、偽の説明図、偽の業務資料、偽の告知画像のような「整った誤情報」の方かもしれません。
便利さが増すほど、見る側には確認の手間が増えます。今回の更新はOpenAIの巻き返しとして見ることができますが、それと同時に、情報がより自然に偽装される環境が強まった節目でもありそうです。
総括
今回の更新で見えてきたのは、画像生成AIの性能向上以上の変化です。生成AIの競争は、目を引く出力を見せる段階から、制作や業務の工程にどこまで入り込めるかを争う段階へ移りつつあります。
OpenAIはその勝負で、これまで弱いと見られていた画像の実用領域を埋めにきました。しかもその流れは、Claude Codeが先に印象づけた「工程を担うAI」の方向とも重なっています。開発でも制作でも、これからのAIは一回ごとの応答より、仕事の流れにどう定着するかで評価されていきそうです。
先に変わるのは、完成作品そのものより、図解、資料、ポスター、販促物、試作案のような中間制作物の領域でしょう。その一方で、整った画像が増えるほど、誤情報や偽資料を見抜く負担も重くなります。
便利さと混乱が同じ速度で進み始めた。そのことをはっきり示したのが、今回のアップデートだったと言えそうです。
それではまた、次回の記事でお会いしましょう。
▼記事が面白かったら応援クリックお願いします!▼


▲更新の励みになります!▲
関連書籍紹介
実践Claude Code入門
西見公宏・吉田真吾・大嶋勇樹(技術評論社/2025年12月26日刊)
今回の記事を読んで、AIが単に答えを返す存在ではなく、実際の作業の流れに入り込み始めていると感じた方におすすめしたい一冊です。開発の現場を題材にしながら、AIエージェントがどのように仕事を進め、どこに強みと限界があるのかを具体的に追えるので、今回の記事で扱った「工程を担うAI」というテーマがより立体的に見えてきます。
画像生成の話を入り口にしていても、いま起きている変化の本質は、文章、調査、コード、画像をまたいでAIが仕事の中に入ってくることにあります。その流れをもう少し実感を持ってつかみたい方には、かなり相性のいい本です。

ディープフェイクの衝撃 AI技術がもたらす破壊と創造
笹原和俊(PHP研究所/2023年2月16日刊)
今回の記事で気になったのが、画像生成AIの便利さよりも、その先にある偽画像や誤情報の問題だった方には、この本がよく刺さると思います。AIが作る映像や画像が社会にどんな影響を与えるのかを、技術の話だけで終わらせず、情報環境や受け手の側の課題まで含めて考えられる内容です。
整った図解やもっともらしいビジュアルが簡単に作れる時代ほど、何を信じるかの判断は難しくなります。今回の記事を読んで、生成AIの進化をただ面白いで終わらせず、その裏側まで知っておきたいと感じた方に手に取ってほしい一冊です。

参考リンク
- Introducing ChatGPT Images 2.0(OpenAI)
- ChatGPT Release Notes(OpenAI Help)
- Introducing GPT-5.5(OpenAI)
- Codex(OpenAI)
- Introducing Codex(OpenAI)
- Claude Code(Anthropic)
- OpenAI Beefs Up ChatGPT’s Image Generation Model(WIRED)
- OpenAI’s new image model aims to make ChatGPT better at graphics and design(The Verge)